“This form of reliability [inter-rater] is an absolute requirement”
(Lyons, 2009, p. 71)
“interrater reliability, even at the individual item level is required”
(Anderson, Lyons, Giles, Price & Estle, 2003, p. 280)
Each version of CANS requires its own testing. Have you tested yours?
The developer has not met the inter-rater reliability criterion he has set as “required” for any version.
There is only one study on reliability (Anderson, Lyons, Giles, Price & Estle, 2003), and the results suggest that CANS is not reliable and/or does not apply to the version you are using. Here is why:
CANS VERSION: Anderson’s study evaluated a 41-item version – a version no longer used. So how can this be cited for validity of the version used today?
RATERS TESTED: It evaluated the reliability between two researchers and a clinician. CANS isn’t used much as a chart review tool anymore. The required evaluation needs to be between two clinicians, each of whom know the case and do their own ratings – an easy study to conduct, yet no one has conducted the study. Have you? Post your story here.
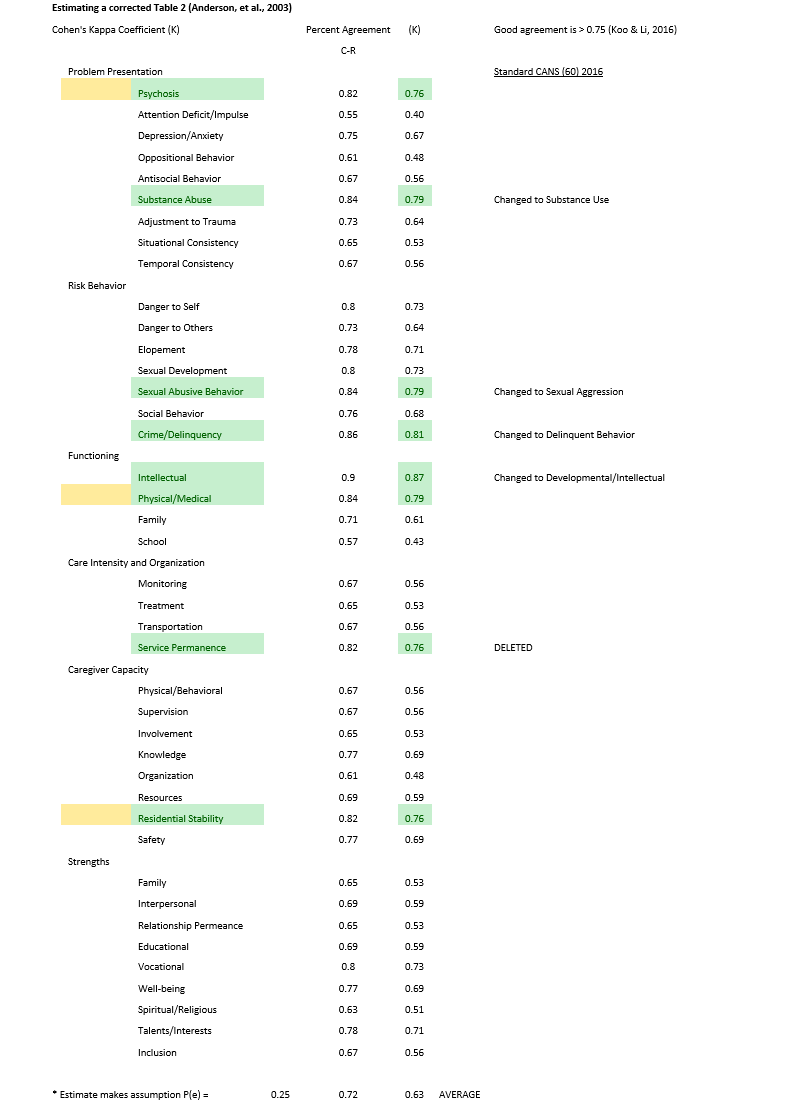
STATISTICS USED: Lyons knows what the right statistics are, but decided to use deceptive “percent agreement” in Table 2. Here is what he knows should have been used: “The two most common [statistics that should be used] are kappa and intraclass correlation coefficients (ICC)” (Lyons, 2009, p. 71). He used neither in presenting the misleading statistics in Table 2 (Anderson, Lyons, Giles, et al., 2003, p. 285), showing instead “percent agreement.” Percent agreement is an overestimate as CANS authors know: “In order to become a Certified Trainer, trainees must achieve a competency of 80% correct [i.e., percent agreement] on two test vignettes, which corresponds to a Kappa value of over 0.75” (Stoner, Leon, Fuller, 2015, p. 787).
View the re-calculated Table 2.
Evaluating Table 2 with the correct standard, only 11 of the 41 items show some reliability, but with the wrong raters evaluated. Further testing and scale development is indicated.
CONCULSIONS MADE: No one has warned the public of these flaws. Instead, Lyons and colleagues point to this paper as evidencing “strong reliability” for any and all versions of CANS (cf. Kisiel, Fehrenbach, Small & Lyons, 2009, p. 147).
Reliability Issues
Lyons claims nothing is more important than excellent inter-rater reliability, even down to the item-level ([03], p. 280). The reason for this is understandable. CANS is explicitly designed so that there is only one item for each domain measured (e.g., depression), and each item/domain is divided into four, discrete “action-level” response choices from “no action” to “intensive or immediate action” required (Lyons, 2009 [34]).
It has long been understood across many fields of study that artificially dividing continuous variables into interval or ordinal scales is problematic with “estimates that tend to be biased and inefficient” and that four-category or fewer indicators should be avoided (Johnson & Creech, 1983, p. 398). Lyons has noted this “substantial simplification”:
The notion that measurement is communication within human service enterprises shifts important aspects of this activity away from the domain of scientists and into the domain of managers. Such a shift requires substantial simplification in order for individuals without scientific training to utilize measurement processes…. ([38], p. 67)
In order for this “substantial simplification” of real-world continuous variables to have any chance of producing meaningful results, we need to know for sure, that we would all agree that those children, labeled by any one of us, as in need of immediate or intensive intervention, really needs that level of intervention. It’s no different than taking gender, height, and weight information and putting all human beings into buckets of under-weight, healthy-weight, over-weight, and morbidly obese. If a substantial number of healthy-weight individuals are really under- or over-weight then we have done nothing to communicate health status to anyone, or move towards improving population health.
“[I]mplications for service planning must be comparable regardless of who is completing the tool; as such, interrater reliability is essential” ([03] p. 282).
[Inter-rater] reliability is an absolute requirement of a communimetric tool. It is impossible to pursue a measurement strategy based on communication that does not consider the accuracy of that communication. The concept of inter-rater reliability in communimetric tools is whether or not two different raters are using the language of the tool in comparable ways…. Of course, the real test of the reliability of any measurement operation is whether it can be accurately applied in the setting where it is actually used. ([34], p. 71-3)
Here, the “setting” is defined by the federal government as Family Courts and using CANS to make LOC determinations. The CANS’ website (praedfoundation.org) claims that the tool has unprecedented clarity:
The average reliability of the CANS is 0.75 with vignettes, 0.84 with case records, and can be above 0.90 with live cases.
The evidence says otherwise, and even strains credulity that the more complicated uses of the tool will have higher inter-rater reliability. For example, “interjudge reliability in assigning a child to an appropriate level of care was close to zero (K = .07).” (Bickman, Karver & Schut, 1997, p. 515). CANS’ developers even cite this statistic ([A], p. 2346). Persons & Bertagnolli (1999) discovered that when trying to make Cognitive-Behavioral schema ratings from audio tapes of interviews, inter-rater reliabilities averaged 0.37 (cf., Persons, Mooney & Padesky, 1995). That was with all raters listening to the same information in the same sequence. When raters must interview and discover “the truth” for themselves, the ratings are less reliable.
The less structured the interview, the poorer the reliabilities. For example, Miller (2001) compared the inter-rater reliability of structured versus unstructured interviews related to diagnosis. They found that traditional, unstructured interviews yielded unacceptable kappa values (0.24 to 0.43) whereas structured interviews could achieve acceptable kappa of 0.75. This strongly suggests that when CANS trains users and then tests them with a one-page vignette, in which all the answers are delivered on one page, this is likely the maximum inter-rater reliabilities, not the floor.
For Family First applications, the appropriately constructed inter-rater reliability test would be to have two different “qualified individuals” (as defined by Congress) interview the family, review the medical record and, blind to each other’s ratings, complete the CANS. Kisiel and colleagues state that completing CANS requires a “two-session intake interview” ([I], p. 17-14). For a sample of sixty subjects this would take about 240 hours of clinical work. Reimbursed at double standard child-welfare rates to $50/hour for professional time and $100/family, the principle data could be collected for less than $20,000. Chapin Hall, the current, exclusive license holder of CANS (Lyons & Israel, 2017 [X], p. 3), has received millions in funding to support the development and installation of CANS — $5,000,000 from just the state of New York (Fernando [Y], 2018). Just one county in California paid more than two million (Alameda [Z], 2018).
CANS’ developers have had more than two decades to conduct this study. Instead, they fabricate statistics (violating RMa). For example, Chor and colleagues claim: “The CANS has also consistently achieved robust item-level inter-rater reliability among researchers (0.81) and between researchers and clinicians (0.85) across CANS domains (Anderson et al. 2003)” ([C], p. 5). Table 1 ([03], p. 284) shows that he has these numbers reversed for CANS total score. Yet, he claims these cited numbers are related to domains scores, which are much lower, ranging from 0.68-0.85. Using the word “consistently” and “robust” is also inappropriate as only one small study is cited and no others are known or found in the literature.
More importantly, the cited study by Anderson [03] must be related to the “setting” under discussion (LOC decisions), and it is not. Anderson was a retrospective chart review study where Lyons’ trained authors/researchers looked at the chart (which included the CANS completed by a clinician) and looked for evidence that their assessments were backed up by relevant notes in the clinical record. For each clinical record reviewed, there were two researchers and one clinician. This un-blinded study had no way to evaluate clinician-to-clinician inter-rater reliabilities. No CANS’ Publication that cites Anderson [03] acknowledges the generalizability or external validity problems when applying the results to modern CANS applications. Nor do they report the findings accurately.
Violating RMa, this begins with the authors (Anderson, Lyons, Giles, Price & Estle [03]) who make false and misleading conclusions that are not supported by the data:
Results of the interrater reliability support previous findings that the CANS-MH is a reliable measure of clinical and psychosocial needs and strengths when used among researchers (Leon et. al., 1999, 2000; Lyons et. al., 1997, 1998, 2000). Results also suggest that ratings on the CANS-MH based on medical record abstraction by researchers relate to ratings performed by clinical staff, demonstrating the clinical and research utility of the CANS-MH. The CANS-MH can be used reliably to assess the type and severity of problem presentation, risk behaviors, functioning, care intensity and organization, caregiver capacity and strengths among children with protective and mental health needs. Findings suggest that the instrument would be useful to assist the ongoing delivery of clinical services such as service planning and clinical decision-making, and serve as an administrative and research tool to monitor quality assurance or assess outcomes. ([03], p. 286)
No study limitations are discussed, and reviewers and readers are led to believe that the five other studies cited were related to CANS. Lyons et al., 1997 [O], for example is a book that reviews a number of tools that could be used to assess outcomes in general practice. CANS was not one of them.
Likely violating RMb, the authors omitted twenty cases from the analysis because of the time burden involved in reviewing all 80 cases; rather, they “randomly” selected 60. They report it only took fifteen minutes to complete CANS, including reviewing the chart, and had access to all necessary charts. The extra five hours of work to eliminate the bias does not look like a legitimate rationale.
Notwithstanding the sweeping conclusions in the Discussion section, the data reported in Table 2, suggests that even this, no-longer-used versions of CANS was not reliable at the item level. First, Anderson used the wrong ICC statistical package from SPSS (“2-way mixed effect model, consistency definition”, [03] p. 283). This ICC statistics assumes that the expert/author/raters of CANS in the research are the only raters who will ever complete CANS. Therefore, the results reported are over-estimated.
Deceptively, when reporting the statistics on individual items, the authors switch from reporting ICC (Intraclass Correlations) to “Percent Agreement” (cf. Table 2, p. 285). Lyons has written about the correct inter-rater reliability statistics in his book (cf. Lyons, 2009 [34], p. 71) and obviously knows better. Fortunately, Cohen’s Kappa is easy to calculate from percent agreement, if we assume that the scores on CANS (0-3) are relatively equally distributed in this clinical population. Converting Table 2 to acceptable inter-rater reliability statistics demonstrates that even when a clinician’s ratings are compared to a researcher’s audit of the clinician’s chart, almost none of the CANS items are reliable. This suggests that for Family First applications, clinician ratings are not reliable and warrant thorough testing before it is used.
More concerning, CANS website now suggests that the designated CANS raters can be non-clinicians: “With training, any one with a bachelor’s degree can learn to complete the tool reliably”, Praed). How a non-clinician could be trained to rate “Psychosis” for example, strains credulity. The CANS’ Manual [W] introduces the Psychosis dimension to raters as follows:
This item rates the symptoms of psychiatric disorders with a known neurological base, including schizophrenia spectrum and other psychotic disorders.
This appears to be a violation of APA Ethical standard (9.07 Assessment by Unqualified Persons), especially since the reliability and validity of this non-standard approach to psychological assessments has not been tested.
Psychologists do not promote the use of psychological assessment techniques by unqualified persons, except when such use is conducted for training purposes with appropriate supervision. (See also Standard 2.05, Delegation of Work to Others.)
CANS claims to test all raters to an ICC of 0.70 before they are certified to use CANS, and explicitly states that until this standard is achieved it is unethical to use the tool. However, we have taken the on-line training course (www.schoox.com), skipped to the test, randomly answered the 42 questions until we were certified within a half hour. The vignettes cycle between six clinical case descriptions that take a maximum of one single typed page. One can re-start the testing and cycle back to the vignette you prefer. One only needs to achieve a score of 0.70 once, and the website ignores all your other tests. The math behind the scoring procedure is also not accurate. At times you can receive a negative “ICC” score and often a score of zero (for example if you select all the same answer, like all “1s”). Once “Certified” you can re-take the test and technically fail, but the Certification is not removed. We were certified by repeatedly cycling back to a vignette about “Lawrence.” His vignette starts off like this:
Lawrence is a 15-year-old boy who last week was found guilty of vandalism and assault. He was convicted of breaking into his school with two friends and vandalizing the hallway walls. He was caught in the act by school security and turned over to the police. He resisted arrest and physically assaulted the security guard whose arm was injured in the event. This incident makes Lawrence at risk of being placed in juvenile detention.
As such, this vignette spoon feeds the rater with the answers to CANS items like Delinquency, Conduct, Anger control and others.